|
|
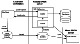
| Figure 6 |
[25] The SPIDR admin web interface has special tools to compare the same databases from several nodes and if necessary to order background synchronization from/to any of them. The inventory-level metadata from the "master'' and "slave'' nodes can be used to compare the data holdings and when there are any differences to start a background process at the "slave'' node, which will pull the locally missing data from the "master'' node using its data source web-service and load it into SPIDR by using the local data sink web-service.
[26] This web-services based synchronization mechanism is a new step in automation of the data exchange between World Data Centers in different countries. The common data model used by all the SPIDR nodes eliminates unnecessary format translations when synchronizing databases at different nodes. The peer-to-peer push synchronization aligns with agency priorities by first loading data into the national "master'' node and then exporting the data to a given list of subscribers abroad. Existence of several copies of the same database in a very distributed network helps ensure long term data preservation.

Powered by TeXWeb (Win32, v.2.0).