System Architecture
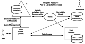
[7] The SPIDR system architecture has the following main components: a web-portal,
metadata repository, visualization and data mining engines, and a grid of virtual
data sources exposed to the external clients including the SPIDR portal via data
query and inject web services. Behind a data source's web service one can have a
database, a set of files in a local to server file system, or a set of URLs to remote
data sources.
SPIDR Portals
[8] A web-portal serves as an agent between the user and the Grid of environmental
data sources. It performs two main functions. The first function is metadata
management, which allows for fast and efficient catalog-level metadata search.
Here by catalog-level metadata we mean general descriptions of data resources,
stored as a managed collection of XML documents with a known XML schemas
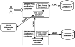
(i.e.. owner info, geographic coverage, time coverage, data description,
visualization methods, etc.). Our catalog-level metadata collection works much
the same as other similar resources, e.g. Global Change Master Directory
(GCMD) from NASA (http://gcmd.nasa.gov).
|
|
Figure 1
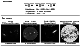
|
[9] The second function of the web-portal is data access. In Figure 1 the
web-portal is shown as a client, which connects to virtual data sources, retrieves the
requested data, and delivers it back to the user. Advanced web-portal functions
can include visualization and data mining. Data access web forms are built using
inventory (or granule-level) metadata describing the availability of stations -
satellites - instruments - parameters or channels for the given time interval. The
inventory metadata can be used also to compare and synchronize mirrored data
sources.
[10] The SPIDR portal combines a central metadata registry with a set of
distributed data web services, web map services, and replica sets of data files. A
user can search catalog-level metadata and inventory, use a persistent data basket
to save the selection between the sessions, and plot or download the selected data
in different formats, including XML and netCDF. A database administrator can
upload files into the SPIDR databases using either a web services or web portal
interface.
Metadata Registry and Data Inventory
[11] Both the catalog- and granule-level metadata records, which contain respectively a
general description and detailed inventory of SPIDR data resources, can be
updated either manually by a system administrator or automatically by the data
robot collecting records from the data grid (see Figure 1). The catalog-level
metadata registry uses a native XML database backend based on the open-source
product eXist [Meier, 2006]. The metadata engine has no predefined XML
schema; it is possible to have different metadata schemas for different data
categories. For example, data sources with spatial content, such as OpenGIS Web
Map Services (http://www.opengeospatial.org/standards/wms) and time series databases
with ground observations, can use FGDC Content Standard for Digital Geospatial Metadata
(document FGDC-STD-001-1998, http://www.fgdc.gov/standards/projects/FGDC-standards-projects/metadata/base-metadata/index_html),
and at the same time databases with satellite telemetry can have SPASE-formatted
metadata records (Space Physics Archive Search and Extract, 2006, http://www.spase-group.org/data/).
The SPIDR high-level metadata engine has
extended search capabilities allowing it to search in specific metadata elements,
(keyword, title, provider, etc.). In addition, it supports Web 2.0 style functionality
with direct editing of the metadata records at the SPIDR portal, a user discussion
forum, internal e-mail messaging, and wiki-style documentation and system help.
[12] The SPIDR granule-level inventory metadata registry uses an SQL
database backend based built on the open-source product MySQL (http://dev.mysql.com/doc/refman/5.0/en/index.html, 2008).
The main purpose of the inventory is to list available parameters and
stations from each database with some granularity in time, currently taken as
monthly. That is whether a given station has any data for a given month. This
information is needed in early validation of data requests for both availability and
size of the data export, and for comparison of data holdings at different SPIDR
nodes for database synchronization. When adding new data to SPIDR, the
inventory can be updated either in real time or by periodic queries of the
corresponding data source, depending on the input data load. At the same time the
inventory metadata is updated the inventory summary such as the station and
parameter list with maximum date ranges is fed up in order to update the
corresponding catalog-level metadata.
Grid of Web-services
|
|
Figure 2
|
[13] Web Services (WS) technology is used by SPIDR to access databases and
metadata both for the SPIDR web application (interactive interface for human
users) and for the SPIDR web clients (third party programs exporting and
importing data and metadata in batch mode). In addition to the WS SOAP
protocol the SPIDR web application can access databases directly using JDBC
drivers. We call the JDBC-connected databases "local'' and the WS-connected
databases "remote'' (Figure 2). The access mode is defined in the database
configuration files. If database is hosted on the server on the same LAN as the
SPIDR web application, then the local access mode may be more efficient
compared to the remote one; but if the database is located outside the local
network then the JDBC connections will be the most probably blocked by a
security considerations and the SOAP protocol becomes the only reliable way to
access the data.
[14] SPIDR data archives are logically organized into thematic groups called
viewGroups (e.g. Geomagnetic Indices, or Interplanetary Magnetic Field). Each
viewGroup may include several databases or groups of database tables, which we
call tables. Each table may be considered as a virtual database with a single
configuration file describing the access mode (local or remote) together with URL
and access credentials.
[15] The system currently has implemented web-services for the following use
cases:
- Get a metadata record for a given viewGroup (Virtual Observatory WS).
- For a given table, element, station and date interval get a data
inventory and export data values in a variety of scientific formats,
including XML and NetCDF (Data Source WS).
- Load several "standard'' data files of several scientific formats into the
database (Data Sink WS).
- Synchronize two SPIDR archives by exporting data from one archive
and loading into another (WS orchestration).
Data Source Web-service.
[16]
Data source web service URLs are stored in SPIDR configuration files. When a
web service call is performed, the web-service returns a URL, pointing to a data
file, containing the serialized CDM object with requested data. The SPIDR
application itself can act as a web-service and process remote calls thus allowing
for chaining of the data export web services.
[17] In any case, a SPIDR data source service will supply metadata describing
parameter names, units of measure, visualization options, etc., and the data
accreditation describing the data origin. Data serialization formats include direct
Java object serialization, XML, NetCDF, and for some databases also special
formats introduced by the data users community. For example, geomagnetic field
variations can be exported in WDC or Intermagnet formats. For geomagnetic
variations the data accreditation describes the observatory which has provided the
data to SPIDR.

|
|
Figure 3
|
[18] With the SPIDR portal, a user can collect the serialized data from the
distributed data sources into a single "user basket'', re-format and re-package all
the data for download, or visualize the selection with multiple time-synchronous
plots either using static GIF images or by dynamic "zoomable'' Java applets which
share the same time scale limits. In Figure 3 we present an example plot of
selections from two databases with planetary geomagnetic disturbance index Kp
and Disturbance Storm Time index DST. Both indices are prime indicators of a
magnetic storm, and the simultaneous plots help to estimate the storm intensity.
[19] Data query options (time interval, data source, parameters, stations) are
saved in the user basket, so the data can be re-selected in the future. Because of
the real-time nature of the SPIDR databases, the data selection itself is transient,
so theoretically in the next session user can find different (updated) observations
in the data basket. All the data selection queries are logged, so the SPIDR
administrator can view not only user session statistics, but also the frequency of
data requests by source.
Satellite Data Granules and Image Archive Web-services.
[20]
Remote sensing and imagery databases have a different data model as compared
to a sequential database. Usually the data collection is divided into "elementary''
blocks called granules. A granule can be a daily set of solar images from different
observatories, or a fixed-length section of satellite orbit with Earth observations in
different spectral bands.
|
|
Figure 4
|
[21] For example, the magnetic storm shown by the time series plots in Figure 4 is
manifested in the daily solar image granule by a bright solar flare in the
164 MHz radiotelescope image. The flare erupts from a large system of sunspots
visible on the solar X-ray and magnetogram images. At the same time,
the aurora produced by this magnetic storm on the night side of the Earth can be
seen at the cloud-free night-time image granules of 1/8th of the DMSP satellite
orbit; one of them is shown in Figure 5.

|
|
Figure 5
|
[22] All the granule-based web-services in SPIDR have the same design
pattern. The user's data export request specifies the date range and type of the
image. The web-service returns a list of granules with metadata and links to the
preview and high-resolution images or binary files for granule data products like
DMSP satellite SSJ/4 sensor readings.
Data Sink Web-service.
[23]
Clients can load data into SPIDR databases from files located on a local
workstation, along with relevant loading options which are passed to the SPIDR
web services together with the data over SOAP with attachments. The database
loading web service called by the client will parse the input file format, load data
into the local database, add a bookkeeping record into the SPIDR data
input/output logging database, and check the list of mirrored SPIDR nodes to send
the input data file there to keep those databases in sync.

Powered by TeXWeb (Win32, v.2.0).